Redis
Redis (Remote Dictionary Server) 是一个开源的内存数据结构存储,用作数据库、缓存和消息代理。它支持多种数据结构,如字符串(strings)、哈希(hashes)、列表(lists)、集合(sets)以及有序集合(sorted sets)。因为具有丰富的功能和高性能,现在几乎主流的 Web 项目都已经绑定了 Redis 作为缓存组件。
title: Redis 官网desc: 点击跳转官网查看详细内容logo: /assets/images/study/persistence/redis/redis-cube.svglink: https://redis.io/color: rgba(173, 216, 590, 0.15)特点
- 内存存储:所有数据都保存在内存中,读写速度非常快,非常适合需要快速响应的场景。
- 持久化:Redis支持将数据持久化到磁盘,可以通过快照(snapshot)和AOF(Append-Only File)两种方式进行。
- 高可用性和分布式:通过 Redis Sentinel 实现高可用,通过Redis Cluster 实现数据分布和负载均衡。
- 丰富的数据类型:支持多种数据结构,便于解决复杂的数据存储和操作问题。
- Lua 脚本:支持 Lua 脚本,可以实现复杂的原子操作。
- 事务支持:支持事务,保证一系列操作的原子性。
常见问题
为什么 Redis 那么快
- 基于内存存储:Redis的所有数据都保存在内存中,读写速度非常快。
- 多路 I/O 复用:Redis 使用多路 I/O 复用技术,可以同时处理多个客户端的请求,提高并发处理能力。
- 高效的数据结构:Redis 支持多种数据结构,这些数据结构都进行了优化,可以快速处理。
- Lua脚本:Redis支持 Lua 脚本,可以实现复杂的原子操作。
- 语言实现:C 语言实现,性能很高。
- 单线程模型:单线程无法充分利用多核,但另一方面,它避免了多线程的频繁上下文切换以及锁等同步机制的开销。
为什么选择单线程
- 避免过多的上下文切换开销:在多线程调度过程中,需要在 CPU 之间切换线程上下文,并且上下文切换涉及一系列寄存器替换、程序堆栈重置,甚至包括程序计数器、堆栈指针和程序状态字等快速表项的退休。因为单个进程内的多个线程共享进程地址空间,线程上下文要比进程上下文小得多,在跨进程调度的情况下,需要切换整个进程地址空间。
- 避免同步机制的开销:如果Redis选择多线程模型,因为 Redis 是一个数据库,不可避免地涉及底层数据同步问题,这必然会引入一些同步机制,如锁。我们知道Redis不仅提供简单的键值数据结构,还提供列表、集合、哈希等丰富的数据结构。不同的数据结构对于同步访问的锁定具有不同的粒度,这可能会在数据操作期间引入大量的锁定和解锁开销,增加了程序的复杂性并降低了性能。
- 简单和可维护性:简单且可维护的代码必然是Redis在早期的核心准则之一,引入多线程不可避免地导致了代码复杂性的增加和可维护性的降低。
Redis 真的是单线程的吗?
需要看版本来说,对于网络模型来说,Redis 在 v6.0 之前一直是单线程的,在 v6.0 之后正式在网络模型中实现I/O多线程;对于整个 Redis 中,在 v4.0 版本中就引入多线程进行异步任务。 Redis在v4.0版本中引入了多线程来执行一些异步操作,主要用于非常耗时的命令。通过将这些命令的执行设置为异步,可以避免阻塞单线程事件循环。
我们知道 Redis 的 DEL 命令用于删除一个或多个键的存储值,它是一个阻塞命令。在大多数情况下,要删除的键不会存储太多值,最多几十个或几百个对象,因此可以快速执行。但如果要删除具有数百万个对象的非常大的键值对,则此命令可能会阻塞至少几秒钟,由于事件循环是单线程的,它会阻塞随后的其他事件,从而降低吞吐量。
为什么要给缓存数据设置过期时间
内存是有限且珍贵的,如果不对缓存数据设置过期时间,那内存占用就会一直增长,最终可能会导致 OOM 问题。通过设置合理的过期时间,Redis 会自动删除暂时不需要的数据,为新的缓存数据腾出空间。 过期时间除了有助于缓解内存的消耗,很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 Token 可能只在 1 天内有效,这些情况都需要设置过期时间来实现业务功能。
Redis 如何判断数据是否过期
Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。 在查询一个 key 的时候,Redis 首先检查该 key 是否存在于过期字典中(时间复杂度为 O(1)),如果不在就直接返回,在的话需要判断一下这个 key 是否过期,过期直接删除 key 然后返回 null。
Redis 删除策略
常用的过期数据的删除策略就下面这几种:
- 惰性删除:只会在取出/查询 key 的时候才对数据进行过期检查。这种方式对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
- 定期删除:周期性地随机从设置了过期时间的 key 中抽查一批,然后逐个检查这些 key 是否过期,过期就删除 key。相比于惰性删除,定期删除对内存更友好,对 CPU 不太友好。
- 延迟队列:把设置过期时间的 key 放到一个延迟队列里,到期之后就删除 key。这种方式可以保证每个过期 key 都能被删除,但维护延迟队列太麻烦,队列本身也要占用资源。
- 定时删除:每个设置了过期时间的 key 都会在设置的时间到达时立即被删除。这种方法可以确保内存中不会有过期的键,但是它对 CPU 的压力最大,因为它需要为每个键都设置一个定时器。
Redis 采用的是 定期删除+惰性/懒汉式删除 结合的策略,这也是大部分缓存框架的选择。定期删除对内存更加友好,惰性删除对 CPU 更加友好。Redis 的定期删除过程是随机的(周期性地随机从设置了过期时间的 key 中抽查一批),所以并不保证所有过期键都会被立即删除。 另外,定期删除还会受到执行时间和过期 key 的比例的影响,执行时间已经超过了阈值,那么就中断这一次定期删除循环,以避免使用过多的 CPU 时间;如果这一批过期的 key 比例超过一个比例,就会重复执行此删除流程,以更积极地清理过期 key。相应地,如果过期的 key 比例低于这个比例,就会中断这一次定期删除循环,避免做过多的工作而获得很少的内存回收。
大量 key 集中过期问题
- 尽量避免 key 集中过期,在设置键的过期时间时尽量随机一点。
- 对过期的 key 开启 lazyfree 机制(修改 redis.conf 中的
lazyfree-lazy-expire参数即可),这样会在后台异步删除过期的 key,不会阻塞主线程的运行。
理论场景
- 缓存(Caching):
- 对需要频繁访问的数据进行缓存,如用户信息、商品信息等。
- 极大提高数据的读取速度,减轻数据库负载。
- 会话存储(Session Store):
- 场景:在Web应用中,将用户会话信息存储在Redis中,如登录状态、购物车等。
- 好处:读取速度快,支持持久化,可以实现分布式会话管理。
- 实时数据分析(Real-time Analytics):
- 场景:用于实时统计和分析,如网站的访问量统计、实时排名等。
- 好处:通过内存操作实现快速数据处理和统计。
- 消息队列(Message Queue):
- 场景:利用Redis的列表(List)或发布/订阅(Pub/Sub)机制实现消息队列,进行异步任务处理。
- 好处:简单易用,适合中小规模的消息队列需求。
- 排行榜(Leaderboard)和计数器(Counting):
- 场景:实现各种排行榜功能,如游戏排名、积分榜等。
- 好处:通过有序集合(sorted set)快速实现排名和分数统计。
- 分布式锁(Distributed Lock):
- 场景:在分布式系统中实现锁机制,确保同一资源不会被多个进程同时修改。
- 好处:利用Redis的原子操作,实现简单有效的分布式锁。
- 地理信息存储和查询(Geospatial Information Storage and Query):
- 场景:存储和查询地理位置数据,如定位服务、地图应用等。
- 好处:通过 geo 命令集快速实现地理位置的存储和半径查询。
- 阅读量/浏览量
- 场景:配合 String 类型的 incr 原子增加操作,每次访问链接自动加一。
- 好处:实现简单,读写速度快。
实际场景
缓存
目前系统的数据访问通常设计有有三种方式,第一种是简单的请求直接访问数据库,如果是在数据量和并发量很小的情况下,这种访问方式是可行的。但是当数据量很大,并发量很高时,这种访问方式就会导致数据库压力过大,从而影响系统的性能。
在这种情况之上就增加了缓存来缓解数据库的压力的第二种方式,请求进入先在缓存中查询数据信息,如果缓存中不存在再去访问数据库数据。这里的方案的实现也有两种:
- 数据结构实现的代码层面的缓存,无论是自定义 Map 存储要缓存的数据,还是使用 Guava 等第三方缓存框架,这种方案的缺点是只能单机使用,并且占用内存会严重些。
- 使用 Redis 作为缓存,天然支持分布式,并且灵活的使用数据结构可以达到优秀的效果,缺点是技术门槛和服务器成本较高。
第三种方式是在缓存的基础上增加布隆过滤器降低无效数据的访问来防止缓存穿透,这种方案的缺点是布隆过滤器需要维护,并且布隆过滤器的误判率需要控制。
布隆过滤器
略
Redis 与数据库读写一致性
这些设计的前提是访问数据库之前先访问 Redis,如果 Redis 不存在再访问数据库。
1. 先写 MySQL,再写 Redis
数据库更新后更新 Redis。在高并发的情况下,如图会出现同时修改数据库和 Redis,导致数据不一致的情况。
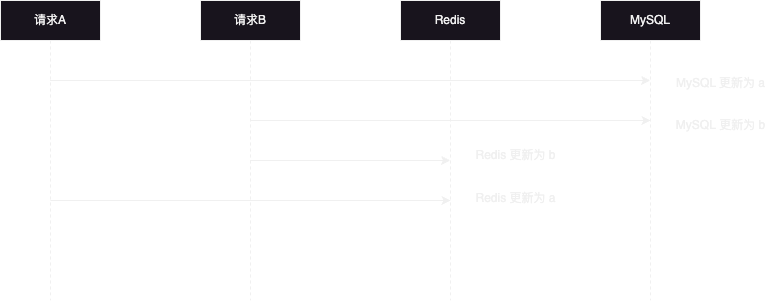
2. 先写 Redis,再写 MySQL
3. 先删除 Redis,再写 MySQL
4. 先写 MySQL,再删除 Redis
上面的方式都会存在不太能接受的数据不一致的情况,而此方案只存在第一次不一致的情况,对于不是强一致性的业务(秒杀、库存服务),可以采用此方案。